Couchbase Analytics Links
S3 + Couchbase Analytics Links 도입기

프롤로그
회사에 AWS DynamoDB를 이용해서 key-value 형태로 JSON 데이터를 저장하는 로직을 개발했습니다. 실제 운영을 해보니 개발과정에서는 생각하지 못한 몇가지 문제가 있었습니다.
- 비용적인 문제
- 항목의 크기 제한
- standalone 개발의 어려움

> 생각 이상으로 DynamoDB는 더 비싸다
DynamoDB 운영 해보니
1. 비용적인 문제
우선 가장 큰 문제는 비용이였습니다. 각 사용자별로 테넌트를 분리를 위해서 각 사용자마다 DynamoDB를 운영하니 굉장히 많은 비용이 발생했습니다.
2. 항목의 크기 제한
하나의 항목의 최대 크기가 400KB 로 제한이 있었기 때문에 더이상 쪼갤수 없는 JSON 데이터를 저장하는데 문제가 있었습니다.
3. standalone 개발의 어려움
회사 서비스는 SaaS 형태 서비스 뿐만 아니라 설치 형태의 standalone 또한 제공하고 있었습니다. 물론 amazon/dynamodb-local를 사용할 수 있습니다. 하지만 이미 SaaS에서는 비용적인 문제로 제거하기로 결론난 상황이였고, standalone 개발에 DynamoDB를 사용해도 추후 유지보수에는 좋지 않은 선택일 확률이 높았습니다.
Couchbase 활용한 AWS 아키텍쳐
DynamoDB를 제거하기 위한 아키텍쳐의 핵심은 S3에 JSON 데이터를 보관하고 이를 활용하는 방안이였습니다. 이를 위해서 Analytics Links 기능을 도입하게 되었습니다.
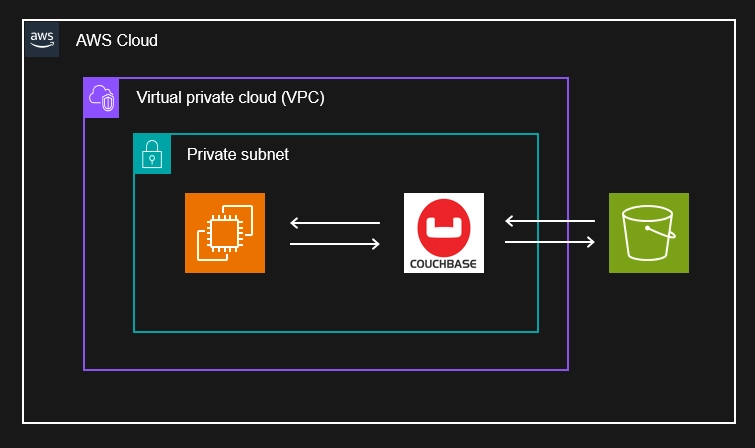
> Analytics Links - s3
Analytics Links
Managing Links 페이지를 참고해서 Couchbase Analytics Links를 사용해보겠습니다.
우선은 왼쪽 사이드바 Analytics 탭에서 링크를 생성하고 관리 할 수 있습니다. 링크를 생성하게 되면 해당 링크의 라벨이 표시되는 것을 알수 있습니다. 특히 퍼블릭 클라우드를 활용한 외부 링크가 눈에 들어오고 여기서는 S3와 링크를 생성해 보도록 하겠습니다.
-
AZUREBLOB: Microsoft Azure Blob storage -
GCS: Google Cloud Storage -
S3: Amazon S3 service
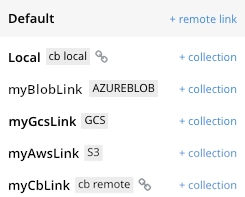
S3 링크 생성
링크를 만들때 필요한 정보는 Access Key ID, Secret Access Key, Region 입니다. 필요한 경우 임시 자격 증명 Session Token 정보까지 입력해 줍니다.
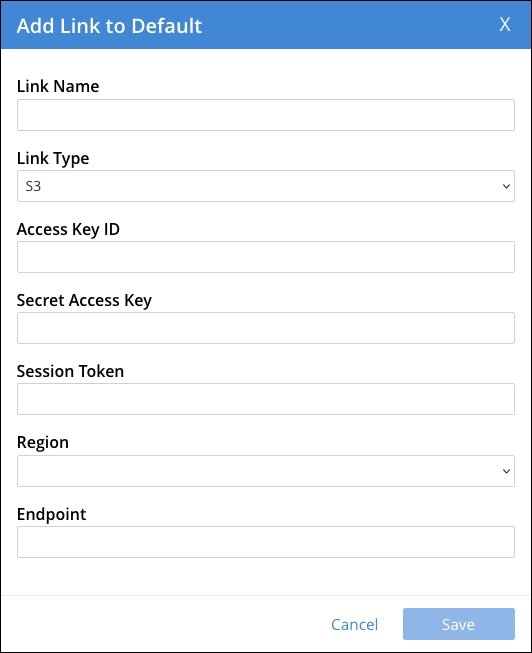
컬렉션(collection) 생성
이제 S3 버킷명과 경로값을 이용해서 컬렉션을 생성해줍니다. 그리고 특정 파일 포맷과 파일명을 지정해서 생성이 가능합니다.
S3 파일 업로드
위 버킷에 아래의 코드로 airline 컬렉션 데이터를 각 파일로 저장해서 업로드 했습니다.
inventory_scope = self.bucket.scope("inventory")
sql_query = "SELECT RAW airline FROM airline"
row_iter = inventory_scope.query(
sql_query,
QueryOptions(positional_parameters=["airline"]),
)
for row in row_iter:
key = row["type"] + str(row["id"])
with open(f"{key}.json", "w") as fp:
logging.info(row)
json.dump(row, fp)
> S3 버킷에 JSON 파일 업로드
SQL++
컬렉션이 제대로 생성된 경우에는 이제 해당 버킷에서 데이터를 가져올 수 있습니다. 가져온 문서의 데이터는 SQL++을 이용하여 처리 할 수 있습니다.
SELECT country
, count(country) as cnt
FROM airline
WHERE country IS NOT NULL
GROUP
BY country
Analytics Links : SDK 개발
앞서 Web Console에서 했던 작업과 동일한 작업을 SDK를 이용하여 python 로직으로 작성해보겠습니다.
컬렉션(collection) 생성
Analytics Links 컬렉션을 SQL++ 에서는 DATASET라고 합니다. create 쿼리를 작성했던것 처럼, analytics_query 메서드를 통해서 쿼리를 실행해 DATASET을 생성 할수 있습니다.
query = """
CREATE EXTERNAL DATASET IF NOT EXISTS `tiaz0128`.`airline`
ON `tiaz0128-couchbase-link`
AT `Default`.`tiaz0128`
USING "airline/"
WITH {"format": "json", "include": "*.json"};
"""
result = cluster.analytics_query(query)
list(result)
result.metadata().status == "success"
데이터 조회 : SQL++
동일하게 analytics_query 메서드를 통해 SQL++ 쿼리를 실행할수 있습니다.
query = """
SELECT country
, count(country) as cnt
FROM airline
WHERE country IS NOT NULL
GROUP
BY country
"""
result = self.cluster.analytics_query(query)
for row in result:
print(row)
{"count": 21,"country": "France"}
{"count": 39,"country": "United Kingdom"}
{"count": 127,"country": "United States"}
에필로그
JSON 데이터를 저장하는 용도로 DynamoDB를 실제 운영환경에서 사용했지만, 여러가지 문제가 있었습니다. 해결 방안의 핵심은 크게 두 가지 였습니다.
- S3에 실제 JSON 데이터 보관
- Analytics Links를 이용한 데이터 조회
실제 JSON 데이터는 AWS S3를 활용하고 데이터를 가져올때는 Analytics Links를 통해서 SQL++을 활용할 수 있어서 좋은 방식인거 같습니다. 😊
